RGI-TOPO for RGI 7.0#
OGGM was used to generate the topography data used to compute the topographical attributes and the centerlines products for RGI v7.0.
Here we show how to access this data from OGGM.
Input parameters#
This notebook can be run as a script with parameters using papermill, but it is not necessary. The following cell contains the parameters you can choose from:
# The RGI Id of the glaciers you want to look for
# Use the original shapefiles or the GLIMS viewer to check for the ID: https://www.glims.org/maps/glims
rgi_id = 'RGI2000-v7.0-G-01-06486' # Denali
# The default is to test for all sources available for this glacier
# Set to a list of source names to override this
sources = None
# Where to write the plots. Default is in the current working directory
plot_dir = f'outputs/{rgi_id}'
# The RGI version to use
# V62 is an unofficial modification of V6 with only minor, backwards compatible modifications
prepro_rgi_version = 62
# Size of the map around the glacier. Currently only 10 and 40 are available
prepro_border = 10
# Degree of processing level. Currently only 1 is available.
from_prepro_level = 1
Check input and set up#
# The sources can be given as parameters
if sources is not None and isinstance(sources, str):
sources = sources.split(',')
# Plotting directory as well
if not plot_dir:
plot_dir = './' + rgi_id
import os
plot_dir = os.path.abspath(plot_dir)
from oggm import cfg, utils, workflow, tasks, graphics, GlacierDirectory
import pandas as pd
import numpy as np
import xarray as xr
import rioxarray as rioxr
import geopandas as gpd
import salem
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import AxesGrid
import itertools
from oggm.utils import DEM_SOURCES
from oggm.workflow import init_glacier_directories
# Make sure the plot directory exists
utils.mkdir(plot_dir);
# Use OGGM to download the data
cfg.initialize()
cfg.PATHS['working_dir'] = utils.gettempdir(dirname='OGGM-RGITOPO-RGI7', reset=True)
cfg.PARAMS['use_intersects'] = False
2024-04-25 13:52:23: oggm.cfg: Reading default parameters from the OGGM `params.cfg` configuration file.
2024-04-25 13:52:23: oggm.cfg: Multiprocessing switched OFF according to the parameter file.
2024-04-25 13:52:23: oggm.cfg: Multiprocessing: using all available processors (N=4)
2024-04-25 13:52:24: oggm.cfg: PARAMS['use_intersects'] changed from `True` to `False`.
Download the data using OGGM utility functions#
Note that you could reach the same goal by downloading the data manually from
# URL of the preprocessed GDirs
gdir_url = 'https://cluster.klima.uni-bremen.de/~oggm/gdirs/oggm_v1.6/rgitopo/2023.1/'
# We use OGGM to download the data
gdir = init_glacier_directories([rgi_id], from_prepro_level=1, prepro_border=10, prepro_rgi_version='70', prepro_base_url=gdir_url)[0]
2024-04-25 13:52:25: oggm.workflow: init_glacier_directories from prepro level 1 on 1 glaciers.
2024-04-25 13:52:25: oggm.workflow: Execute entity tasks [gdir_from_prepro] on 1 glaciers
2024-04-25 13:52:25: oggm.utils: Downloading https://cluster.klima.uni-bremen.de/~oggm/gdirs/oggm_v1.6/rgitopo/2023.1/RGI70/b_010/L1/RGI2000-v7.0-G-01/RGI2000-v7.0-G-01-06.tar to /github/home/OGGM/download_cache/cluster.klima.uni-bremen.de/~oggm/gdirs/oggm_v1.6/rgitopo/2023.1/RGI70/b_010/L1/RGI2000-v7.0-G-01/RGI2000-v7.0-G-01-06.tar...
2024-04-25 13:52:35: oggm.utils: Downloading https://cluster.klima.uni-bremen.de/~fmaussion/misc/rgi7_data/00_rgi70_regions/00_rgi70_O1Regions/00_rgi70_O1Regions.dbf to /github/home/OGGM/download_cache/cluster.klima.uni-bremen.de/~fmaussion/misc/rgi7_data/00_rgi70_regions/00_rgi70_O1Regions/00_rgi70_O1Regions.dbf...
2024-04-25 13:52:36: oggm.utils: Downloading https://cluster.klima.uni-bremen.de/~fmaussion/misc/rgi7_data/00_rgi70_regions/00_rgi70_O2Regions/00_rgi70_O2Regions.dbf to /github/home/OGGM/download_cache/cluster.klima.uni-bremen.de/~fmaussion/misc/rgi7_data/00_rgi70_regions/00_rgi70_O2Regions/00_rgi70_O2Regions.dbf...
gdir
<oggm.GlacierDirectory>
RGI id: RGI2000-v7.0-G-01-06486
Region: 01: Alaska
Subregion: 01-02: Alaska Range (Wrangell/Kilbuck)
Glacier type: Glacier
Terminus type: Not assigned
Status: Glacier
Area: 0.961122833004822 km2
Lon, Lat: (-151.0094740399913, 63.061062)
Grid (nx, ny): (70, 88)
Grid (dx, dy): (24.0, -24.0)
Read the DEMs and store them all in a dataset#
if sources is None:
sources = [src for src in os.listdir(gdir.dir) if src in utils.DEM_SOURCES]
print('RGI ID:', rgi_id)
print('Available DEM sources:', sources)
print('Plotting directory:', plot_dir)
RGI ID: RGI2000-v7.0-G-01-06486
Available DEM sources: ['ARCTICDEM', 'MAPZEN', 'AW3D30', 'ALASKA', 'COPDEM90', 'COPDEM30', 'ASTER', 'DEM3', 'TANDEM']
Plotting directory: /__w/tutorials/tutorials/notebooks/tutorials/outputs/RGI2000-v7.0-G-01-06486
# We use xarray to store the data
ods = xr.Dataset()
for src in sources:
demfile = os.path.join(gdir.dir, src) + '/dem.tif'
with rioxr.open_rasterio(demfile) as ds:
data = ds.sel(band=1).load() * 1.
ods[src] = data.where(data > -100, np.NaN)
sy, sx = np.gradient(ods[src], gdir.grid.dx, gdir.grid.dx)
ods[src + '_slope'] = ('y', 'x'), np.arctan(np.sqrt(sy**2 + sx**2))
with rioxr.open_rasterio(gdir.get_filepath('glacier_mask')) as ds:
ods['mask'] = ds.sel(band=1).load()
# Decide on the number of plots and figure size
ns = len(sources)
x_size = 12
n_cols = 3
n_rows = -(-ns // n_cols)
y_size = x_size / n_cols * n_rows
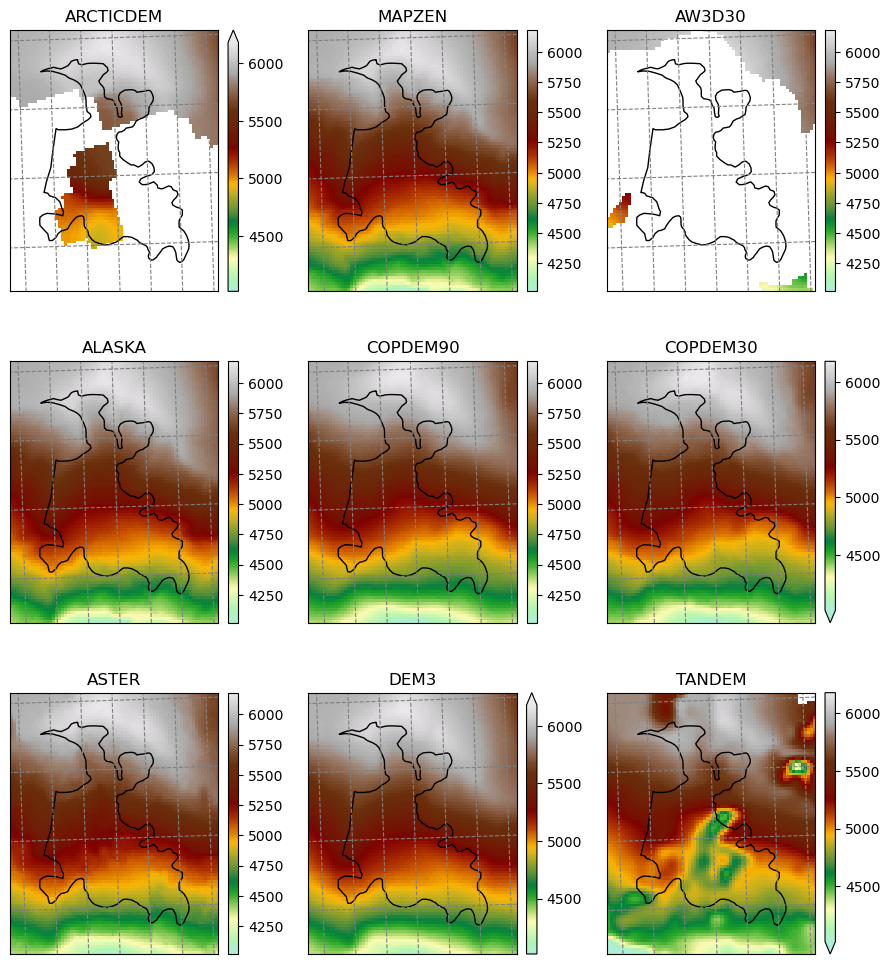
Raw topography data#
smap = salem.graphics.Map(gdir.grid, countries=False)
smap.set_shapefile(gdir.read_shapefile('outlines'))
smap.set_plot_params(cmap='topo')
smap.set_lonlat_contours(add_tick_labels=False)
smap.set_plot_params(vmin=np.nanquantile([ods[s].min() for s in sources], 0.25),
vmax=np.nanquantile([ods[s].max() for s in sources], 0.75))
fig = plt.figure(figsize=(x_size, y_size))
grid = AxesGrid(fig, 111,
nrows_ncols=(n_rows, n_cols),
axes_pad=0.7,
cbar_mode='each',
cbar_location='right',
cbar_pad=0.1
)
for i, s in enumerate(sources):
data = ods[s]
smap.set_data(data)
ax = grid[i]
smap.visualize(ax=ax, addcbar=False, title=s)
if np.isnan(data).all():
grid[i].cax.remove()
continue
cax = grid.cbar_axes[i]
smap.colorbarbase(cax)
# take care of uneven grids
if ax != grid[-1] and not grid[-1].title.get_text():
grid[-1].remove()
grid[-1].cax.remove()
if ax != grid[-2] and not grid[-2].title.get_text():
grid[-2].remove()
grid[-2].cax.remove()
plt.savefig(os.path.join(plot_dir, 'dem_topo_color.png'), dpi=150, bbox_inches='tight')
Shaded relief#
fig = plt.figure(figsize=(x_size, y_size))
grid = AxesGrid(fig, 111,
nrows_ncols=(n_rows, n_cols),
axes_pad=0.7,
cbar_location='right',
cbar_pad=0.1
)
smap.set_plot_params(cmap='Blues')
smap.set_shapefile()
for i, s in enumerate(sources):
data = ods[s].copy().where(np.isfinite(ods[s]), 0)
smap.set_data(data * 0)
ax = grid[i]
smap.set_topography(data)
smap.visualize(ax=ax, addcbar=False, title=s)
# take care of uneven grids
if ax != grid[-1] and not grid[-1].title.get_text():
grid[-1].remove()
grid[-1].cax.remove()
if ax != grid[-2] and not grid[-2].title.get_text():
grid[-2].remove()
grid[-2].cax.remove()
plt.savefig(os.path.join(plot_dir, 'dem_topo_shade.png'), dpi=150, bbox_inches='tight')

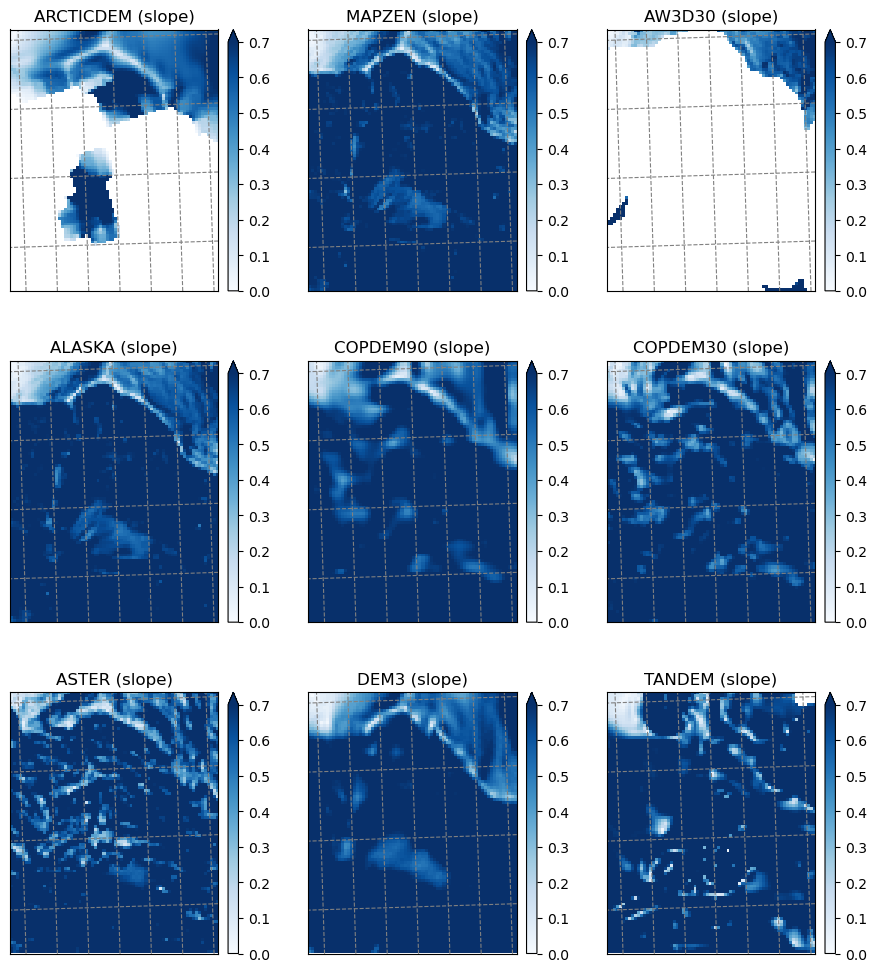
Slope#
fig = plt.figure(figsize=(x_size, y_size))
grid = AxesGrid(fig, 111,
nrows_ncols=(n_rows, n_cols),
axes_pad=0.7,
cbar_mode='each',
cbar_location='right',
cbar_pad=0.1
)
smap.set_topography();
smap.set_plot_params(vmin=0, vmax=0.7, cmap='Blues')
for i, s in enumerate(sources):
data = ods[s + '_slope']
smap.set_data(data)
ax = grid[i]
smap.visualize(ax=ax, addcbar=False, title=s + ' (slope)')
cax = grid.cbar_axes[i]
smap.colorbarbase(cax)
# take care of uneven grids
if ax != grid[-1] and not grid[-1].title.get_text():
grid[-1].remove()
grid[-1].cax.remove()
if ax != grid[-2] and not grid[-2].title.get_text():
grid[-2].remove()
grid[-2].cax.remove()
plt.savefig(os.path.join(plot_dir, 'dem_slope.png'), dpi=150, bbox_inches='tight')
Some simple statistics about the DEMs#
df = pd.DataFrame()
for s in sources:
df[s] = ods[s].data.flatten()[ods.mask.data.flatten() == 1]
dfs = pd.DataFrame()
for s in sources:
dfs[s] = ods[s + '_slope'].data.flatten()[ods.mask.data.flatten() == 1]
dfs = df.describe()
dfs.loc['range'] = dfs.loc['max'] - dfs.loc['min']
dfs
| ARCTICDEM | MAPZEN | AW3D30 | ALASKA | COPDEM90 | COPDEM30 | ASTER | DEM3 | TANDEM | |
|---|---|---|---|---|---|---|---|---|---|
| count | 767.000000 | 1671.000000 | 0.0 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 |
| mean | 5529.413086 | 5319.226212 | NaN | 5316.735352 | 5277.694824 | 5277.514160 | 5295.587672 | 5328.549372 | 5153.806152 |
| std | 393.222015 | 350.840381 | NaN | 351.459656 | 370.293671 | 370.142792 | 351.229245 | 351.724101 | 388.357605 |
| min | 4871.422852 | 4622.000000 | NaN | 4610.906738 | 4584.852539 | 4585.657715 | 4565.000000 | 4644.000000 | 4497.636719 |
| 25% | 5111.490234 | 5050.000000 | NaN | 5047.515381 | 4980.320312 | 4982.135010 | 5026.500000 | 5058.000000 | 4837.172607 |
| 50% | 5613.539551 | 5258.000000 | NaN | 5255.337402 | 5231.637207 | 5231.779785 | 5250.000000 | 5259.000000 | 5044.266113 |
| 75% | 5869.918945 | 5578.500000 | NaN | 5578.190430 | 5564.726562 | 5562.813232 | 5543.000000 | 5590.000000 | 5441.289551 |
| max | 6126.963379 | 6111.000000 | NaN | 6116.865234 | 6073.276855 | 6073.898438 | 6113.000000 | 6120.000000 | 5975.219727 |
| range | 1255.540527 | 1489.000000 | NaN | 1505.958496 | 1488.424316 | 1488.240723 | 1548.000000 | 1476.000000 | 1477.583008 |
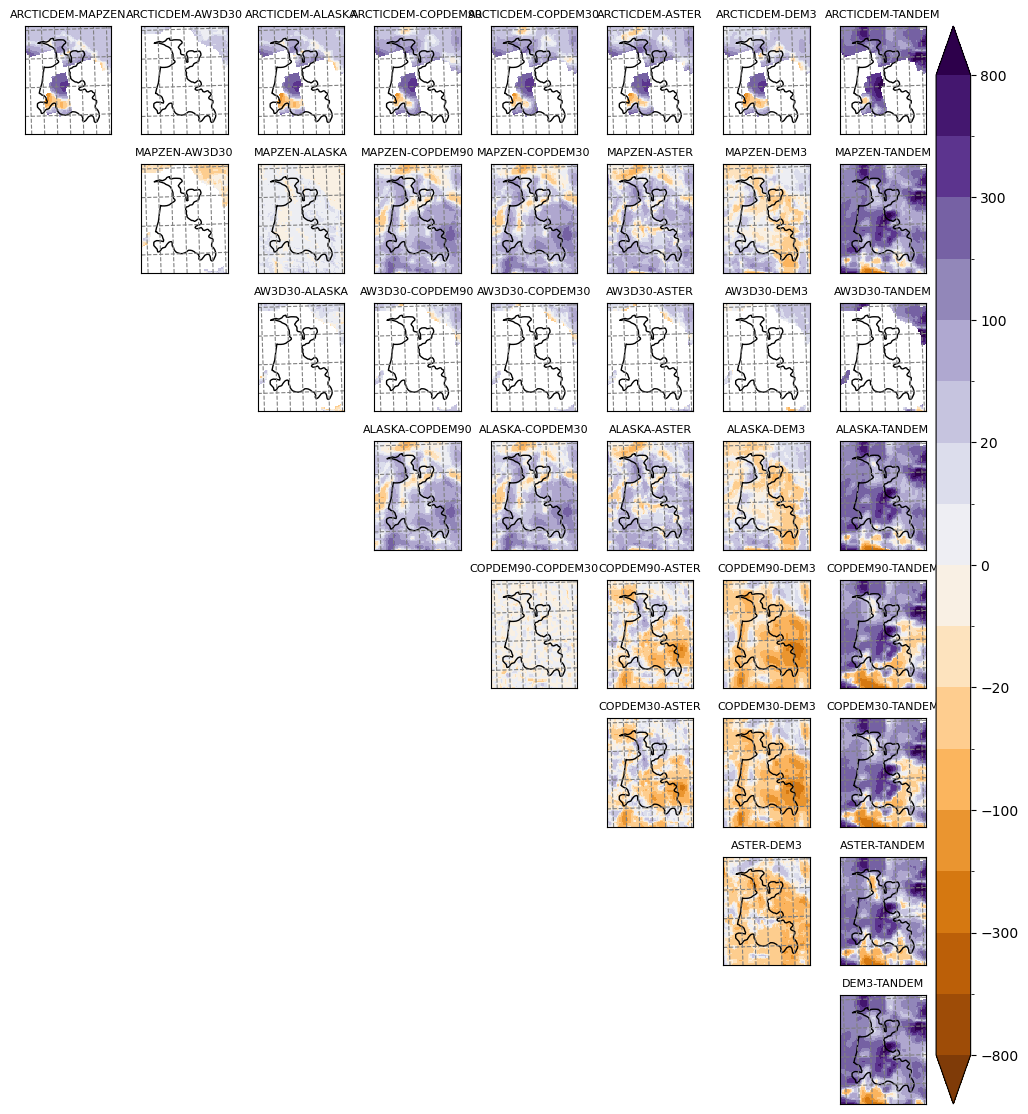
Comparison matrix plot#
# Table of differences between DEMS
df_diff = pd.DataFrame()
done = []
for s1, s2 in itertools.product(sources, sources):
if s1 == s2:
continue
if (s2, s1) in done:
continue
df_diff[s1 + '-' + s2] = df[s1] - df[s2]
done.append((s1, s2))
# Decide on plot levels
max_diff = df_diff.quantile(0.99).max()
base_levels = np.array([-8, -5, -3, -1.5, -1, -0.5, -0.2, -0.1, 0, 0.1, 0.2, 0.5, 1, 1.5, 3, 5, 8])
if max_diff < 10:
levels = base_levels
elif max_diff < 100:
levels = base_levels * 10
elif max_diff < 1000:
levels = base_levels * 100
else:
levels = base_levels * 1000
levels = [l for l in levels if abs(l) < max_diff]
if max_diff > 10:
levels = [int(l) for l in levels]
levels
[-800,
-500,
-300,
-150,
-100,
-50,
-20,
-10,
0,
10,
20,
50,
100,
150,
300,
500,
800]
smap.set_plot_params(levels=levels, cmap='PuOr', extend='both')
smap.set_shapefile(gdir.read_shapefile('outlines'))
fig = plt.figure(figsize=(14, 14))
grid = AxesGrid(fig, 111,
nrows_ncols=(ns - 1, ns - 1),
axes_pad=0.3,
cbar_mode='single',
cbar_location='right',
cbar_pad=0.1
)
done = []
for ax in grid:
ax.set_axis_off()
for s1, s2 in itertools.product(sources, sources):
if s1 == s2:
continue
if (s2, s1) in done:
continue
data = ods[s1] - ods[s2]
ax = grid[sources.index(s1) * (ns - 1) + sources[1:].index(s2)]
ax.set_axis_on()
smap.set_data(data)
smap.visualize(ax=ax, addcbar=False)
done.append((s1, s2))
ax.set_title(s1 + '-' + s2, fontsize=8)
cax = grid.cbar_axes[0]
smap.colorbarbase(cax);
plt.savefig(os.path.join(plot_dir, 'dem_diffs.png'), dpi=150, bbox_inches='tight')
Comparison scatter plot#
import seaborn as sns
sns.set(style="ticks")
l1, l2 = (utils.nicenumber(df.min().min(), binsize=50, lower=True),
utils.nicenumber(df.max().max(), binsize=50, lower=False))
def plot_unity(xdata, ydata, **kwargs):
points = np.linspace(l1, l2, 100)
plt.gca().plot(points, points, color='k', marker=None,
linestyle=':', linewidth=3.0)
g = sns.pairplot(df.dropna(how='all', axis=1).dropna(), plot_kws=dict(s=50, edgecolor="C0", linewidth=1));
g.map_offdiag(plot_unity)
for asx in g.axes:
for ax in asx:
ax.set_xlim((l1, l2))
ax.set_ylim((l1, l2))
plt.savefig(os.path.join(plot_dir, 'dem_scatter.png'), dpi=150, bbox_inches='tight')
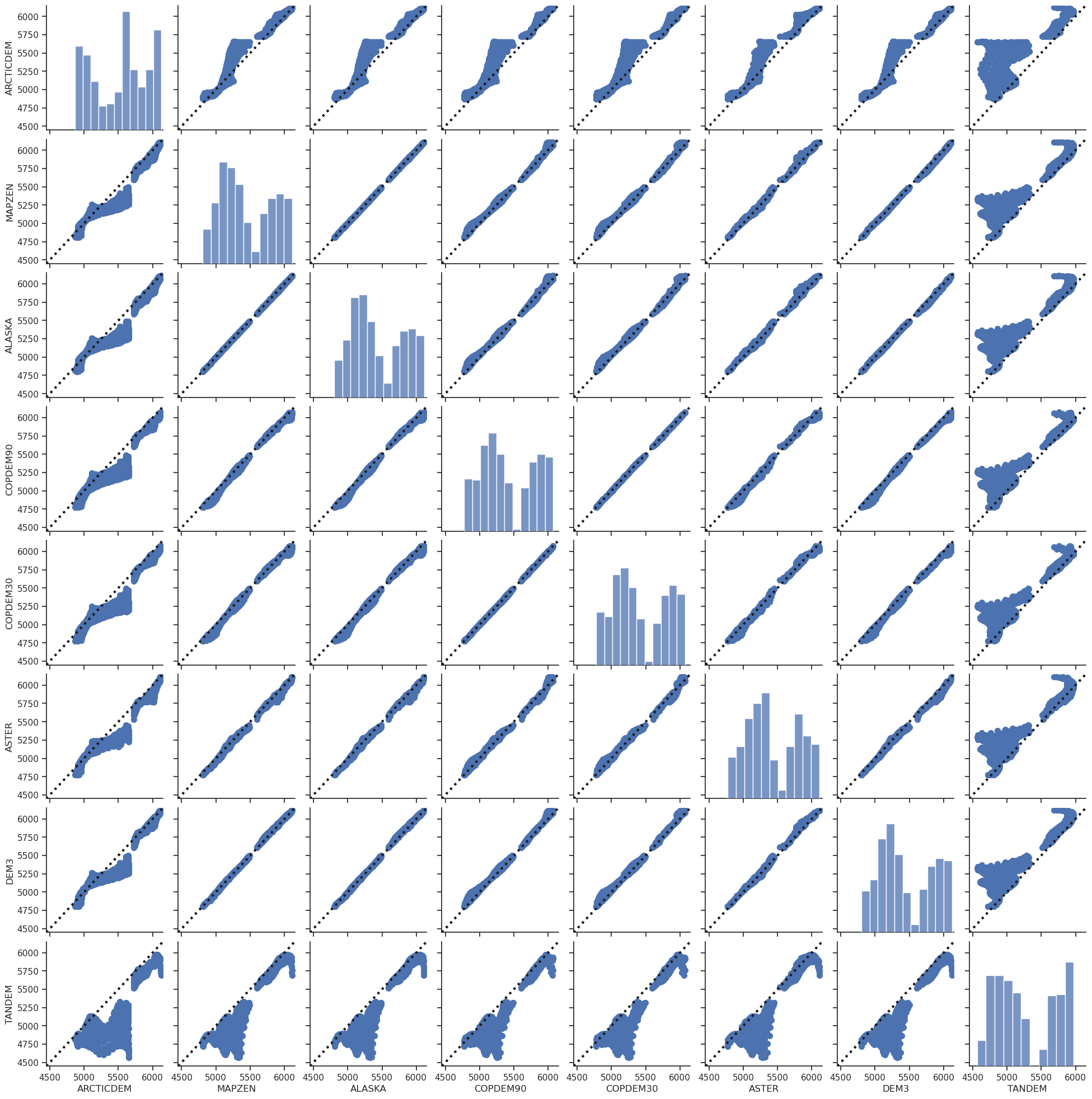
Table statistics#
df.describe()
| ARCTICDEM | MAPZEN | AW3D30 | ALASKA | COPDEM90 | COPDEM30 | ASTER | DEM3 | TANDEM | |
|---|---|---|---|---|---|---|---|---|---|
| count | 767.000000 | 1671.000000 | 0.0 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 |
| mean | 5529.413086 | 5319.226212 | NaN | 5316.735352 | 5277.694824 | 5277.514160 | 5295.587672 | 5328.549372 | 5153.806152 |
| std | 393.222015 | 350.840381 | NaN | 351.459656 | 370.293671 | 370.142792 | 351.229245 | 351.724101 | 388.357605 |
| min | 4871.422852 | 4622.000000 | NaN | 4610.906738 | 4584.852539 | 4585.657715 | 4565.000000 | 4644.000000 | 4497.636719 |
| 25% | 5111.490234 | 5050.000000 | NaN | 5047.515381 | 4980.320312 | 4982.135010 | 5026.500000 | 5058.000000 | 4837.172607 |
| 50% | 5613.539551 | 5258.000000 | NaN | 5255.337402 | 5231.637207 | 5231.779785 | 5250.000000 | 5259.000000 | 5044.266113 |
| 75% | 5869.918945 | 5578.500000 | NaN | 5578.190430 | 5564.726562 | 5562.813232 | 5543.000000 | 5590.000000 | 5441.289551 |
| max | 6126.963379 | 6111.000000 | NaN | 6116.865234 | 6073.276855 | 6073.898438 | 6113.000000 | 6120.000000 | 5975.219727 |
df.corr()
| ARCTICDEM | MAPZEN | AW3D30 | ALASKA | COPDEM90 | COPDEM30 | ASTER | DEM3 | TANDEM | |
|---|---|---|---|---|---|---|---|---|---|
| ARCTICDEM | 1.000000 | 0.957611 | NaN | 0.957513 | 0.957821 | 0.957143 | 0.960869 | 0.957046 | 0.858754 |
| MAPZEN | 0.957611 | 1.000000 | NaN | 0.999929 | 0.996033 | 0.995645 | 0.997390 | 0.998911 | 0.930963 |
| AW3D30 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ALASKA | 0.957513 | 0.999929 | NaN | 1.000000 | 0.996075 | 0.995697 | 0.997280 | 0.998666 | 0.930687 |
| COPDEM90 | 0.957821 | 0.996033 | NaN | 0.996075 | 1.000000 | 0.999891 | 0.995702 | 0.995559 | 0.928387 |
| COPDEM30 | 0.957143 | 0.995645 | NaN | 0.995697 | 0.999891 | 1.000000 | 0.995283 | 0.995141 | 0.928303 |
| ASTER | 0.960869 | 0.997390 | NaN | 0.997280 | 0.995702 | 0.995283 | 1.000000 | 0.997277 | 0.923299 |
| DEM3 | 0.957046 | 0.998911 | NaN | 0.998666 | 0.995559 | 0.995141 | 0.997277 | 1.000000 | 0.934220 |
| TANDEM | 0.858754 | 0.930963 | NaN | 0.930687 | 0.928387 | 0.928303 | 0.923299 | 0.934220 | 1.000000 |
df_diff.describe()
| ARCTICDEM-MAPZEN | ARCTICDEM-AW3D30 | ARCTICDEM-ALASKA | ARCTICDEM-COPDEM90 | ARCTICDEM-COPDEM30 | ARCTICDEM-ASTER | ARCTICDEM-DEM3 | ARCTICDEM-TANDEM | MAPZEN-AW3D30 | MAPZEN-ALASKA | ... | COPDEM90-COPDEM30 | COPDEM90-ASTER | COPDEM90-DEM3 | COPDEM90-TANDEM | COPDEM30-ASTER | COPDEM30-DEM3 | COPDEM30-TANDEM | ASTER-DEM3 | ASTER-TANDEM | DEM3-TANDEM | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 767.000000 | 0.0 | 767.000000 | 767.000000 | 767.000000 | 767.000000 | 767.000000 | 767.000000 | 0.0 | 1671.000000 | ... | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 |
| mean | 83.946521 | NaN | 85.975136 | 110.184074 | 110.319916 | 102.185113 | 76.316795 | 251.653717 | NaN | 2.490369 | ... | 0.180525 | -17.892747 | -50.854447 | 123.888710 | -18.073272 | -51.034972 | 123.708183 | -32.961700 | 141.781450 | 174.743149 |
| std | 113.273900 | NaN | 113.401764 | 113.430321 | 114.278862 | 108.948818 | 114.381777 | 224.423676 | NaN | 4.234587 | ... | 5.457573 | 38.488241 | 38.750864 | 144.647827 | 39.801988 | 40.056016 | 144.721756 | 25.941984 | 149.341491 | 138.969170 |
| min | -146.276367 | NaN | -147.653809 | -131.313965 | -136.359863 | -121.276367 | -151.276367 | -48.799805 | NaN | -14.705078 | ... | -17.572266 | -124.032227 | -163.009766 | -78.665039 | -128.154297 | -173.853027 | -84.786133 | -128.000000 | -85.662109 | -14.181152 |
| 25% | 4.010010 | NaN | 5.880127 | 36.502441 | 35.619141 | 28.157715 | -1.839355 | 111.032227 | NaN | 0.054199 | ... | -2.751221 | -40.641357 | -74.026611 | 17.190430 | -42.359863 | -73.800049 | 18.154541 | -48.000000 | 44.948730 | 84.589355 |
| 50% | 56.379883 | NaN | 58.945312 | 81.454102 | 82.882324 | 71.489746 | 38.955078 | 170.058594 | NaN | 2.204590 | ... | 0.013672 | -12.738770 | -39.517090 | 95.284180 | -13.353027 | -39.264160 | 95.392578 | -29.000000 | 100.195801 | 133.516602 |
| 75% | 143.172607 | NaN | 143.909668 | 158.221924 | 158.155029 | 171.116211 | 139.544922 | 358.547607 | NaN | 5.209473 | ... | 3.210938 | 7.423828 | -23.536377 | 179.401855 | 8.449463 | -22.958496 | 178.104980 | -19.000000 | 193.438232 | 217.682861 |
| max | 396.646973 | NaN | 401.538574 | 452.215332 | 459.774902 | 428.646973 | 399.646973 | 1085.924805 | NaN | 20.434082 | ... | 18.569824 | 111.338867 | 17.004395 | 812.890137 | 123.904297 | 26.395508 | 812.099121 | 52.000000 | 829.932129 | 872.888672 |
8 rows × 36 columns
df_diff.abs().describe()
| ARCTICDEM-MAPZEN | ARCTICDEM-AW3D30 | ARCTICDEM-ALASKA | ARCTICDEM-COPDEM90 | ARCTICDEM-COPDEM30 | ARCTICDEM-ASTER | ARCTICDEM-DEM3 | ARCTICDEM-TANDEM | MAPZEN-AW3D30 | MAPZEN-ALASKA | ... | COPDEM90-COPDEM30 | COPDEM90-ASTER | COPDEM90-DEM3 | COPDEM90-TANDEM | COPDEM30-ASTER | COPDEM30-DEM3 | COPDEM30-TANDEM | ASTER-DEM3 | ASTER-TANDEM | DEM3-TANDEM | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 767.000000 | 0.0 | 767.000000 | 767.000000 | 767.000000 | 767.000000 | 767.000000 | 767.000000 | 0.0 | 1671.000000 | ... | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 | 1671.000000 |
| mean | 103.447394 | NaN | 105.086456 | 117.711647 | 118.163139 | 112.711556 | 95.275925 | 253.502304 | NaN | 3.799071 | ... | 4.060298 | 31.869296 | 51.431971 | 134.962799 | 32.801881 | 52.023959 | 135.184494 | 35.226212 | 147.605664 | 174.815853 |
| std | 95.769833 | NaN | 95.936180 | 105.587395 | 106.137970 | 98.004051 | 99.124644 | 222.330795 | NaN | 3.113807 | ... | 3.649907 | 28.025463 | 37.980538 | 134.367798 | 28.886490 | 38.762088 | 134.057739 | 22.770194 | 143.584187 | 138.877648 |
| min | 0.289062 | NaN | 0.155273 | 0.624512 | 0.650879 | 0.155762 | 0.184570 | 0.293457 | NaN | 0.002930 | ... | 0.000488 | 0.000000 | 0.002441 | 0.050781 | 0.005371 | 0.012207 | 0.002441 | 0.000000 | 0.175293 | 0.848633 |
| 25% | 33.356445 | NaN | 36.557861 | 41.026611 | 41.187012 | 41.791260 | 21.433594 | 111.032227 | NaN | 1.328125 | ... | 1.359131 | 10.204102 | 23.536377 | 38.032227 | 11.155762 | 23.231689 | 38.805664 | 20.000000 | 49.170898 | 84.589355 |
| 50% | 64.257812 | NaN | 65.577148 | 82.970215 | 84.257812 | 73.289062 | 52.738770 | 170.058594 | NaN | 3.072266 | ... | 2.911621 | 22.945801 | 39.517090 | 95.284180 | 23.466309 | 39.264160 | 95.392578 | 29.000000 | 100.195801 | 133.516602 |
| 75% | 144.176514 | NaN | 144.205811 | 158.221924 | 158.155029 | 171.116211 | 141.093506 | 358.547607 | NaN | 5.534912 | ... | 5.748779 | 46.310059 | 74.026611 | 179.401855 | 47.615723 | 73.800049 | 178.104980 | 48.000000 | 193.438232 | 217.682861 |
| max | 396.646973 | NaN | 401.538574 | 452.215332 | 459.774902 | 428.646973 | 399.646973 | 1085.924805 | NaN | 20.434082 | ... | 18.569824 | 124.032227 | 163.009766 | 812.890137 | 128.154297 | 173.853027 | 812.099121 | 128.000000 | 829.932129 | 872.888672 |
8 rows × 36 columns
What’s next?#
return to the OGGM documentation
back to the table of contents