Merge, analyse and visualize OGGM GCM runs#
In this notebook we want to show:
How to merge the output of different OGGM GCM projections into one dataset
How to calculate regional values (e.g. volume) using the merged dataset
How to use matplotlib or seaborn to visualize the projections and plot different statistical estimates (median, interquartile range, mean, std, …)
How to use HoloViews and Panel to visualize the outcome. This part uses advanced plotting capabilities which are not necessary to understand the rest of the notebook.
This notebook is intended to explain the postprocessing steps, rather than the OGGM workflow itself. Therefore some code (especially conducting the GCM projection runs) does not have many explanations. If you are more interested in these steps you should check out the notebook Run OGGM with GCM data.
GCM projection runs#
The first step is to conduct the GCM projection runs. We choose two different glaciers by their rgi_ids and conduct the GCM projections. Again if you do not understand all of the following code you should check out the Run OGGM with GCM data notebook.
# Libs
from time import gmtime, strftime
import xarray as xr
import numpy as np
# Locals
from oggm import utils, workflow, tasks, DEFAULT_BASE_URL
import oggm.cfg as cfg
from oggm.shop import gcm_climate
Pre-processed directories#
# Initialize OGGM and set up the default run parameters
cfg.initialize(logging_level='WARNING')
# change border around the individual glaciers
cfg.PARAMS['border'] = 80
# Use Multiprocessing
cfg.PARAMS['use_multiprocessing'] = True
# For hydro output
cfg.PARAMS['store_model_geometry'] = True
# Local working directory (where OGGM will write its output)
cfg.PATHS['working_dir'] = utils.gettempdir('OGGM_merge_gcm_runs', reset=True)
# RGI glaciers: Ngojumba and Khumbu
rgi_ids = utils.get_rgi_glacier_entities(['RGI60-15.03473', 'RGI60-15.03733'])
# Go - get the pre-processed glacier directories
# in OGGM v1.6 you have to explicitly indicate the url from where you want to start from
# we will use here the elevation band flowlines which are much simpler than the centerlines
gdirs = workflow.init_glacier_directories(rgi_ids, from_prepro_level=5, prepro_base_url=DEFAULT_BASE_URL)
2024-04-25 13:38:03: oggm.cfg: Reading default parameters from the OGGM `params.cfg` configuration file.
2024-04-25 13:38:03: oggm.cfg: Multiprocessing switched OFF according to the parameter file.
2024-04-25 13:38:03: oggm.cfg: Multiprocessing: using all available processors (N=4)
2024-04-25 13:38:04: oggm.cfg: Multiprocessing switched ON after user settings.
2024-04-25 13:38:04: oggm.cfg: PARAMS['store_model_geometry'] changed from `False` to `True`.
2024-04-25 13:38:10: oggm.workflow: init_glacier_directories from prepro level 5 on 2 glaciers.
2024-04-25 13:38:10: oggm.workflow: Execute entity tasks [gdir_from_prepro] on 2 glaciers
Download and process GCM data#
In this notebook, we will use the bias-corrected ISIMIP3b GCM files. You can also use directly CMIP5 or CMIP6 (how to do that is explained in run_with_gcm).
all_GCM = ['gfdl-esm4_r1i1p1f1', 'ipsl-cm6a-lr_r1i1p1f1',
'mpi-esm1-2-hr_r1i1p1f1',
'mri-esm2-0_r1i1p1f1', 'ukesm1-0-ll_r1i1p1f2']
# define the SSP scenarios
all_scenario = ['ssp126', 'ssp370', 'ssp585']
for GCM in all_GCM:
for ssp in all_scenario:
# we will pretend that 'mpi-esm1-2-hr_r1i1p1f1' is missing for `ssp370`
# to later show how to deal with missing values,
# if you want to use this
# code you can of course remove the "if" and just download all GCMs and SSPS
if (ssp == 'ssp370') & (GCM=='mpi-esm1-2-hr_r1i1p1f1'):
pass
else:
# Download and process them:
workflow.execute_entity_task(gcm_climate.process_monthly_isimip_data, gdirs,
ssp = ssp,
# gcm ensemble -> you can choose another one
member=GCM,
# recognize the climate file for later
output_filesuffix=f'_{GCM}_{ssp}'
);
# you could create a similar workflow with CMIP5 or CMIP6
2024-04-25 13:38:10: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:38:23: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:38:30: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:38:36: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:38:49: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:38:55: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:39:01: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:39:14: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:39:20: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:39:21: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:39:22: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:39:23: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:39:36: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
2024-04-25 13:39:42: oggm.workflow: Execute entity tasks [process_monthly_isimip_data] on 2 glaciers
Here we defined, downloaded and processed all the GCM models and scenarios (here 5 GCMs and three SSPs). We pretend that one GCM is missing for one scenario (this is sometimes the case in for example CMIP5 GCMs, see e.g. this table). We deal with possible missing GCMs for specific SCENARIOs by by including a try/except in the code below and by taking care that the missing values are filled with NaN values (and stay NaN when doing sums).
Actual projection Runs#
Now we conduct the actual projection runs. Again handling the case that for a certain (GCM, SCENARIO) combination no data is available with a try/except.
for GCM in all_GCM:
for scen in all_scenario:
rid = '_{}_{}'.format(GCM, scen)
try: # check if (GCM, scen) combination exists
workflow.execute_entity_task(tasks.run_with_hydro, gdirs,
run_task=tasks.run_from_climate_data,
ys=2020, # star year of our projection runs
climate_filename='gcm_data', # use gcm_data, not climate_historical
climate_input_filesuffix=rid, # use the chosen GCM and scenario
init_model_filesuffix='_spinup_historical', # this is important! Start from 2020 glacier
output_filesuffix=rid, # the filesuffix of the resulting file, so we can find it later
store_monthly_hydro=True
);
except FileNotFoundError:
# if a certain scenario is not available for a GCM we land here
# and we inidcate this by printing a message so the user knows
# this scenario is missing
# (in this case of course, the file actually is available, but we just pretend that it is not...)
print('No ' + GCM +' run with scenario ' + scen + ' available!')
No mpi-esm1-2-hr_r1i1p1f1 run with scenario ssp370 available!
2024-04-25 13:39:48: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:49: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:50: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:51: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:52: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:53: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:54: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:55: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:55: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:56: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:56: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:57: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:58: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:39:59: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
2024-04-25 13:40:00: oggm.workflow: Execute entity tasks [run_with_hydro] on 2 glaciers
Merge datasets together#
Now that we have conducted the projection Runs we can start merging all outputs into one dataset. The individual files can be opened by providing the output_filesuffix of the projection runs as the input_filesuffix. Let us have a look at one resulting dataset!
file_id = '_{}_{}'.format(all_GCM[0], all_scenario[0])
ds = utils.compile_run_output(gdirs, input_filesuffix=file_id)
ds
2024-04-25 13:40:01: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:01: oggm.utils: Applying compile_run_output on 2 gdirs.
<xarray.Dataset> Size: 118kB
Dimensions: (time: 82, rgi_id: 2, month_2d: 12)
Coordinates:
* time (time) float64 656B 2.02e+03 ... 2.101e+03
* rgi_id (rgi_id) <U14 112B 'RGI60-15.03473' 'RGI60-...
hydro_year (time) int64 656B 2020 2021 2022 ... 2100 2101
hydro_month (time) int64 656B 4 4 4 4 4 4 ... 4 4 4 4 4 4
calendar_year (time) int64 656B 2020 2021 2022 ... 2100 2101
calendar_month (time) int64 656B 1 1 1 1 1 1 ... 1 1 1 1 1 1
* month_2d (month_2d) int64 96B 1 2 3 4 5 ... 9 10 11 12
calendar_month_2d (month_2d) int64 96B 1 2 3 4 5 ... 9 10 11 12
Data variables: (12/24)
volume (time, rgi_id) float64 1kB 7.282e+09 ... 1....
volume_bsl (time, rgi_id) float64 1kB 0.0 0.0 ... 0.0 0.0
volume_bwl (time, rgi_id) float64 1kB 0.0 0.0 ... 0.0 0.0
area (time, rgi_id) float64 1kB 6.09e+07 ... 1.6...
length (time, rgi_id) float64 1kB 2.094e+04 ... 9....
calving (time, rgi_id) float64 1kB 0.0 0.0 ... 0.0 0.0
... ...
liq_prcp_on_glacier_monthly (time, month_2d, rgi_id) float64 16kB 0.0 ....
snowfall_off_glacier_monthly (time, month_2d, rgi_id) float64 16kB 1.071...
snowfall_on_glacier_monthly (time, month_2d, rgi_id) float64 16kB 2.219...
water_level (rgi_id) float64 16B 0.0 0.0
glen_a (rgi_id) float64 16B 1.635e-23 1.653e-23
fs (rgi_id) float64 16B 0.0 0.0
Attributes:
description: OGGM model output
oggm_version: 1.6.2.dev35+g7489be1
calendar: 365-day no leap
creation_date: 2024-04-25 13:40:01We see that as a result, we get a xarray.Dataset. We also see that this dataset has three dimensions time, rgi_id and month_2d. When we look at the Data variables (click to expand) we can see that for each of these variables a certain combination of the dimensions is given. For example, for the volume we see the dimensions (time, rgi_id) which indicates that the underlying data is separated by each year and each glacier. Let’s have a look at the volume in 2030 and 2040 at the glacier ‘RGI60-15.03473’ (Ngojumba):
ds['volume'].loc[{'time': [2030, 2040], 'rgi_id': ['RGI60-15.03473' ]}]
<xarray.DataArray 'volume' (time: 2, rgi_id: 1)> Size: 16B
array([[6.72036822e+09],
[6.08729763e+09]])
Coordinates:
* time (time) float64 16B 2.03e+03 2.04e+03
* rgi_id (rgi_id) <U14 56B 'RGI60-15.03473'
hydro_year (time) int64 16B 2030 2040
hydro_month (time) int64 16B 4 4
calendar_year (time) int64 16B 2030 2040
calendar_month (time) int64 16B 1 1
Attributes:
description: Total glacier volume
unit: m 3A more complete overview of how to access the data of xarray Dataset can be found here.
This is quite useful, but unfortunately, we have one xarray Dataset for each (GCM, SCENARIO) pair. For an easier calculation and comparison between different GCMs and Scenarios(here SSPs), it would be desirable to combine all individual Datasets into one Dataset with the additional dimensions (GCM, SCENARIO). Fortunately, xarray provides different functions to merge Datasets (here you can find an Overview).
In our case, we want to merge all individual datasets with two additional coordinates GCM and SCENARIO. Additional coordinates can be added with the comment .coords[], also you can include a description with .coords[].attrs['description']. For example, let us add GCM as a new coordinate:
ds.coords['GCM'] = all_GCM[0]
ds.coords['GCM'].attrs['description'] = 'Global Circulation Model'
ds
<xarray.Dataset> Size: 118kB
Dimensions: (time: 82, rgi_id: 2, month_2d: 12)
Coordinates:
* time (time) float64 656B 2.02e+03 ... 2.101e+03
* rgi_id (rgi_id) <U14 112B 'RGI60-15.03473' 'RGI60-...
hydro_year (time) int64 656B 2020 2021 2022 ... 2100 2101
hydro_month (time) int64 656B 4 4 4 4 4 4 ... 4 4 4 4 4 4
calendar_year (time) int64 656B 2020 2021 2022 ... 2100 2101
calendar_month (time) int64 656B 1 1 1 1 1 1 ... 1 1 1 1 1 1
* month_2d (month_2d) int64 96B 1 2 3 4 5 ... 9 10 11 12
calendar_month_2d (month_2d) int64 96B 1 2 3 4 5 ... 9 10 11 12
GCM <U18 72B 'gfdl-esm4_r1i1p1f1'
Data variables: (12/24)
volume (time, rgi_id) float64 1kB 7.282e+09 ... 1....
volume_bsl (time, rgi_id) float64 1kB 0.0 0.0 ... 0.0 0.0
volume_bwl (time, rgi_id) float64 1kB 0.0 0.0 ... 0.0 0.0
area (time, rgi_id) float64 1kB 6.09e+07 ... 1.6...
length (time, rgi_id) float64 1kB 2.094e+04 ... 9....
calving (time, rgi_id) float64 1kB 0.0 0.0 ... 0.0 0.0
... ...
liq_prcp_on_glacier_monthly (time, month_2d, rgi_id) float64 16kB 0.0 ....
snowfall_off_glacier_monthly (time, month_2d, rgi_id) float64 16kB 1.071...
snowfall_on_glacier_monthly (time, month_2d, rgi_id) float64 16kB 2.219...
water_level (rgi_id) float64 16B 0.0 0.0
glen_a (rgi_id) float64 16B 1.635e-23 1.653e-23
fs (rgi_id) float64 16B 0.0 0.0
Attributes:
description: OGGM model output
oggm_version: 1.6.2.dev35+g7489be1
calendar: 365-day no leap
creation_date: 2024-04-25 13:40:01You can see that now GCM is added as Coordinate, but when you look at the Data variables you see that this new Coordinate is not used by any of them. So we must add this new Coordinate to the Data variables using the .expand_dims() comment:
ds = ds.expand_dims('GCM')
ds
<xarray.Dataset> Size: 118kB
Dimensions: (time: 82, rgi_id: 2, month_2d: 12, GCM: 1)
Coordinates:
* time (time) float64 656B 2.02e+03 ... 2.101e+03
* rgi_id (rgi_id) <U14 112B 'RGI60-15.03473' 'RGI60-...
hydro_year (time) int64 656B 2020 2021 2022 ... 2100 2101
hydro_month (time) int64 656B 4 4 4 4 4 4 ... 4 4 4 4 4 4
calendar_year (time) int64 656B 2020 2021 2022 ... 2100 2101
calendar_month (time) int64 656B 1 1 1 1 1 1 ... 1 1 1 1 1 1
* month_2d (month_2d) int64 96B 1 2 3 4 5 ... 9 10 11 12
calendar_month_2d (month_2d) int64 96B 1 2 3 4 5 ... 9 10 11 12
* GCM (GCM) <U18 72B 'gfdl-esm4_r1i1p1f1'
Data variables: (12/24)
volume (GCM, time, rgi_id) float64 1kB 7.282e+09 ....
volume_bsl (GCM, time, rgi_id) float64 1kB 0.0 ... 0.0
volume_bwl (GCM, time, rgi_id) float64 1kB 0.0 ... 0.0
area (GCM, time, rgi_id) float64 1kB 6.09e+07 .....
length (GCM, time, rgi_id) float64 1kB 2.094e+04 ....
calving (GCM, time, rgi_id) float64 1kB 0.0 ... 0.0
... ...
liq_prcp_on_glacier_monthly (GCM, time, month_2d, rgi_id) float64 16kB ...
snowfall_off_glacier_monthly (GCM, time, month_2d, rgi_id) float64 16kB ...
snowfall_on_glacier_monthly (GCM, time, month_2d, rgi_id) float64 16kB ...
water_level (GCM, rgi_id) float64 16B 0.0 0.0
glen_a (GCM, rgi_id) float64 16B 1.635e-23 1.653e-23
fs (GCM, rgi_id) float64 16B 0.0 0.0
Attributes:
description: OGGM model output
oggm_version: 1.6.2.dev35+g7489be1
calendar: 365-day no leap
creation_date: 2024-04-25 13:40:01Now we see that GCM was added to the Dimensions and all Data variables now use this new coordinate. The same can be done with SCENARIO. As a standalone, this is not very useful. But if we add these coordinates to all datasets, it becomes quite handy for merging. Therefore we now open all datasets and add to each one the two coordinates GCM and SCENARIO:
Add new coordinates#
ds_all = [] # in this array all datasets going to be stored with additional coordinates GCM and SCENARIO
creation_date = strftime("%Y-%m-%d %H:%M:%S", gmtime()) # here add the current time for info
for GCM in all_GCM: # loop through all GCMs
for scen in all_scenario: # loop through all SSPs
try: # check if GCM, SCENARIO combination exists
rid = '_{}_{}'.format(GCM, scen) # put together the same filesuffix which was used during the projection runs
ds_tmp = utils.compile_run_output(gdirs, input_filesuffix=rid) # open one model run
ds_tmp.coords['GCM'] = GCM # add GCM as a coordinate
ds_tmp.coords['GCM'].attrs['description'] = 'used Global circulation Model' # add a description for GCM
ds_tmp = ds_tmp.expand_dims("GCM") # add GCM as a dimension to all Data variables
ds_tmp.coords['SCENARIO'] = scen # add scenario (here ssp) as a coordinate
ds_tmp.coords['SCENARIO'].attrs['description'] = 'used scenario (here SSPs)'
ds_tmp = ds_tmp.expand_dims("SCENARIO") # add SSO as a dimension to all Data variables
ds_tmp.attrs['creation_date'] = creation_date # also add todays date for info
ds_all.append(ds_tmp) # add the dataset with extra coordinates to our final ds_all array
except RuntimeError as err: # here we land if an error occured
if str(err) == 'Found no valid glaciers!': # This is the error message if the GCM, SCENARIO (here ssp) combination does not exist
print(f'No data for GCM {GCM} with SCENARIO {scen} found!') # print a descriptive message
else:
raise RuntimeError(err) # if an other error occured we just raise it
No data for GCM mpi-esm1-2-hr_r1i1p1f1 with SCENARIO ssp370 found!
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:02: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:02: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:03: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:03: oggm.utils: Applying compile_run_output on 2 gdirs.
2024-04-25 13:40:03: oggm.utils: Applying global task compile_run_output on 2 glaciers
2024-04-25 13:40:03: oggm.utils: Applying compile_run_output on 2 gdirs.
Actual merging#
ds_all now contains all outputs with the additionally added coordinates. Now we can merge them with the very convenient xarray function xr.combine_by_coords():
ds_merged = xr.combine_by_coords(ds_all, fill_value=np.nan) # define how the missing GCM, SCENARIO combinations should be filled
Great! You see that the result is one Dataset, but we still can identify the individual runs with the two additionally added Coordinates GCM and SCENARIO (SSP). If you want to save this new Dataset for later analysis you can use for example .to_netcdf() (here you can find an Overview of xarray writing options):
ds_merged.to_netcdf('merged_GCM_projections.nc')
And to open it again later and automatically close the file after reading you can use:
with xr.open_dataset('merged_GCM_projections.nc') as ds:
ds_merged = ds
Calculate regional values#
Now we have our merged dataset and we can start with the analysis. To do this xarray gives us a ton of different mathematical functions which can be used directly with our dataset. Here you can find a great overview of what is possible.
As an example, we could calculate the mean and std of the total regional glacier volume for different scenarios of our merged dataset. Here our added coordinates come in very handy. However, for a small amount of GCMs (for ISIMIP3b e.g. 5 GCMs), it is often better to compute instead more robust estimates, such as the median, the 25th and 75th percentile or the total range. We will show different options later:
Let us start by calculating the total “regional” glacier volume using .sum() (of course, here it is just the sum over two glaciers…):
# the missing values were filled with np.NaN values for all time points and glaciers
assert np.all(np.isnan(ds_merged['volume'].sel(SCENARIO='ssp370').sel(GCM='mpi-esm1-2-hr_r1i1p1f1')))
# So, what happens to the missing GCM and ssp if we just do the sum?
ds_total_volume_wrong = ds_merged['volume'].sum(dim='rgi_id', # over which dimension the sum should be taken, here we want to sum up over all glacier ids
keep_attrs=True) # keep the variable descriptions
ds_total_volume_wrong.sel(SCENARIO='ssp370').sel(GCM='mpi-esm1-2-hr_r1i1p1f1')
<xarray.DataArray 'volume' (time: 82)> Size: 656B
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
Coordinates:
* time (time) float64 656B 2.02e+03 2.021e+03 ... 2.1e+03 2.101e+03
SCENARIO <U6 24B 'ssp370'
GCM <U22 88B 'mpi-esm1-2-hr_r1i1p1f1'
hydro_year (time) int64 656B 2020 2021 2022 2023 ... 2099 2100 2101
hydro_month (time) int64 656B 4 4 4 4 4 4 4 4 4 4 ... 4 4 4 4 4 4 4 4 4
calendar_year (time) int64 656B 2020 2021 2022 2023 ... 2099 2100 2101
calendar_month (time) int64 656B 1 1 1 1 1 1 1 1 1 1 ... 1 1 1 1 1 1 1 1 1
Attributes:
description: Total glacier volume
unit: m 3At least in my xarray version, this creates a volume of “0”. That is not desirable, the sum over NaN, should give a NaN.
To be sure that this happens, you should add the keyword arguments skipna=True and min_count=amount_of_rgi_ids:
ds_total_volume = ds_merged['volume'].sum(dim='rgi_id', # over which dimension the sum should be taken, here we want to sum up over all glacier ids
skipna=True, # ignore nan values
# important, we need values for every glacier (here 2) to do the sum
# if some have NaN, the sum should also be NaN (if you don't set min_count, the sum will be 0, which is bad)
min_count=len(ds_merged.rgi_id),
keep_attrs=True) # keep the variable descriptions
# perfect, now, the `NaN` is preserved!
assert np.all(np.isnan(ds_total_volume.sel(SCENARIO='ssp370').sel(GCM='mpi-esm1-2-hr_r1i1p1f1')))
To conclude, for this calculation:
we told xarray over which dimension we want to sum up
dim='rgi_id'(all glaciers),that missing values should be ignored
skipna=True(as some GCM/SCENARIO combinations are not available),defined the minimum amount of required observations to do the operation (i.e. here we need at least two observations that are not
NaN),and that the attributes (the description of the variables) should be preserved
keep_attrs=True. You can see that the result has three dimensions left(GCM, time, SCENARIO)and the dimensionrgi_iddisappeared as we have summed all values up along this dimension.
Likewise, we can now calculate for example the median of all GCM runs:
ds_total_volume_median = ds_total_volume.median(dim='GCM', # over which dimension the median should be calculated
skipna=True, # ignore nan values
keep_attrs=True) # keep all variable descriptions
ds_total_volume_median
<xarray.DataArray 'volume' (SCENARIO: 3, time: 82)> Size: 2kB
array([[9.12019126e+09, 9.05315203e+09, 9.05262684e+09, 8.98343274e+09,
8.92535914e+09, 8.87664049e+09, 8.80281726e+09, 8.71581110e+09,
8.62922690e+09, 8.53685435e+09, 8.44480923e+09, 8.38146184e+09,
8.31680704e+09, 8.23998031e+09, 8.19300600e+09, 8.08855617e+09,
8.02838610e+09, 7.92323397e+09, 7.82935048e+09, 7.71782596e+09,
7.57920701e+09, 7.51117715e+09, 7.46848652e+09, 7.41815427e+09,
7.34651749e+09, 7.24265025e+09, 7.13788073e+09, 7.06425161e+09,
6.98344104e+09, 6.93181658e+09, 6.84604597e+09, 6.76303901e+09,
6.67422871e+09, 6.61870358e+09, 6.60919014e+09, 6.52730287e+09,
6.48140770e+09, 6.41410797e+09, 6.30217892e+09, 6.24431915e+09,
6.16250633e+09, 6.06136517e+09, 5.98572253e+09, 5.91450413e+09,
5.84064782e+09, 5.76423196e+09, 5.66403138e+09, 5.60715617e+09,
5.52601171e+09, 5.55914974e+09, 5.45751256e+09, 5.40072400e+09,
5.33345384e+09, 5.23613712e+09, 5.20335055e+09, 5.15984242e+09,
5.13179417e+09, 5.10593768e+09, 5.07268235e+09, 5.04423644e+09,
5.02692505e+09, 5.01309508e+09, 4.97617663e+09, 4.92387421e+09,
4.89473171e+09, 4.85094017e+09, 4.85381579e+09, 4.86206584e+09,
4.83478030e+09, 4.79748108e+09, 4.78575938e+09, 4.79582042e+09,
4.83824682e+09, 4.83108097e+09, 4.79610555e+09, 4.83883123e+09,
4.91051110e+09, 4.94823678e+09, 4.94644888e+09, 4.95291288e+09,
...
8.86764126e+09, 8.79289933e+09, 8.74645842e+09, 8.66400948e+09,
8.59025276e+09, 8.46855650e+09, 8.41724661e+09, 8.37155958e+09,
8.32047683e+09, 8.24688916e+09, 8.18065695e+09, 8.09482779e+09,
8.01628940e+09, 7.94075755e+09, 7.86982520e+09, 7.75373133e+09,
7.71694806e+09, 7.65098091e+09, 7.42871900e+09, 7.22671566e+09,
7.09312172e+09, 6.90883834e+09, 6.73620664e+09, 6.60954060e+09,
6.49676550e+09, 6.41334843e+09, 6.34082044e+09, 6.23367465e+09,
6.11745551e+09, 6.03386782e+09, 5.87890882e+09, 5.75078219e+09,
5.65594539e+09, 5.53011636e+09, 5.41455181e+09, 5.25955924e+09,
5.08474376e+09, 4.96969856e+09, 4.76877813e+09, 4.61942571e+09,
4.50880920e+09, 4.37991783e+09, 4.25438065e+09, 4.12655491e+09,
3.99635810e+09, 3.90505209e+09, 3.78303077e+09, 3.68673858e+09,
3.56984029e+09, 3.46608134e+09, 3.38828680e+09, 3.28580424e+09,
3.20374897e+09, 3.15951037e+09, 3.10862165e+09, 3.05926068e+09,
2.98736809e+09, 2.98074087e+09, 2.97210279e+09, 2.95457038e+09,
2.89320910e+09, 2.82285486e+09, 2.77478274e+09, 2.75619478e+09,
2.67147302e+09, 2.61458953e+09, 2.56197988e+09, 2.52699869e+09,
2.48081629e+09, 2.42604440e+09, 2.42574320e+09, 2.38596726e+09,
2.40117263e+09, 2.32190843e+09, 2.25415457e+09, 2.22314059e+09,
2.20728768e+09, 2.19519392e+09]])
Coordinates:
* time (time) float64 656B 2.02e+03 2.021e+03 ... 2.1e+03 2.101e+03
* SCENARIO (SCENARIO) <U6 72B 'ssp126' 'ssp370' 'ssp585'
hydro_year (time) int64 656B 2020 2021 2022 2023 ... 2099 2100 2101
hydro_month (time) int64 656B 4 4 4 4 4 4 4 4 4 4 ... 4 4 4 4 4 4 4 4 4
calendar_year (time) int64 656B 2020 2021 2022 2023 ... 2099 2100 2101
calendar_month (time) int64 656B 1 1 1 1 1 1 1 1 1 1 ... 1 1 1 1 1 1 1 1 1
Attributes:
description: Total glacier volume
unit: m 3And you see that now we are left with two dimensions (SCENARIO, time). This means we have calculated the median total volume for all different scenarios (here SSPs) and along the projection period. The mean, standard deviation (std) or percentiles can be also calculated in the same way as the median. Again, bare in mind, that for small sample sizes of GCM ensembles (around 15), which is almost always the case, it is often much more robust to use median and the interquartile range or other percentile ranges.
Visualisation with matplotlib or seaborn#
We will first use matplotlib, where we need to estimate the statistical estimates ourselves. This is good to understand what we are doing.
import matplotlib.pyplot as plt
# estimate the minimum volume for each time step and scenario over the GCMs
ds_total_volume_min = ds_total_volume.min(dim='GCM', keep_attrs=True,skipna=True)
# estimate the 25th percentile volume for each time step and scenario over the GCMs
ds_total_volume_p25 = ds_total_volume.quantile(0.25, dim='GCM', keep_attrs=True,skipna=True)
# estimate the 50th percentile volume for each time step and scenario over the GCMs
ds_total_volume_p50 = ds_total_volume.quantile(0.5, dim='GCM', keep_attrs=True,skipna=True)
# this is the same as the median -> Let's check
np.testing.assert_allclose(ds_total_volume_median,ds_total_volume_p50)
# estimate the 75th percentile volume for each time step and scenario over the GCMs
ds_total_volume_p75 = ds_total_volume.quantile(0.75, dim='GCM', keep_attrs=True,skipna=True)
# estimate the maximum volume for each time step and scenario over the GCMs
ds_total_volume_max = ds_total_volume.max(dim='GCM', keep_attrs=True,skipna=True)
# Think twice if it is appropriate to compute a mean/std over your GCM sample, is it Gaussian distributed?
# Otherwise use instead median and percentiles or total range
ds_total_volume_mean = ds_total_volume.mean(dim='GCM', keep_attrs=True,
skipna=True)
ds_total_volume_std = ds_total_volume.std(dim='GCM', keep_attrs=True,
skipna=True)
color_dict={'ssp126':'blue', 'ssp370':'orange', 'ssp585':'red'}
fig, axs = plt.subplots(1,2, figsize=(12,6),
sharey=True # we want to share the y axis betweeen the subplots
)
for scenario in color_dict.keys():
# get amount of GCMs per Scenario to add it to the legend:
n = len(ds_total_volume.sel(SCENARIO=scenario).dropna(dim='GCM').GCM)
axs[0].plot(ds_total_volume_median.time,
ds_total_volume_median.sel(SCENARIO=scenario)/1e9, # m3 -> km3
label=f'{scenario}: n={n} GCMs',
color=color_dict[scenario],lw=3)
axs[0].fill_between(ds_total_volume_median.time,
ds_total_volume_p25.sel(SCENARIO=scenario)/1e9,
ds_total_volume_p75.sel(SCENARIO=scenario)/1e9,
color=color_dict[scenario],
alpha=0.5,
label='interquartile range\n(75th-25th percentile)')
axs[0].fill_between(ds_total_volume_median.time,
ds_total_volume_min.sel(SCENARIO=scenario)/1e9,
ds_total_volume_max.sel(SCENARIO=scenario)/1e9,
color=color_dict[scenario],
alpha=0.1,
label='total range')
for scenario in color_dict.keys():
axs[1].plot(ds_total_volume_mean.time,
ds_total_volume_mean.sel(SCENARIO=scenario)/1e9, # m3 -> km3
color=color_dict[scenario],
label='mean',lw=3)
axs[1].fill_between(ds_total_volume_mean.time,
ds_total_volume_mean.sel(SCENARIO=scenario)/1e9 - ds_total_volume_std.sel(SCENARIO=scenario)/1e9,
ds_total_volume_mean.sel(SCENARIO=scenario)/1e9 + ds_total_volume_std.sel(SCENARIO=scenario)/1e9,
alpha=0.3,
color=color_dict[scenario],
label='standard deviation')
for ax in axs:
# get all handles and labels and then create two different legends
handles, labels = ax.get_legend_handles_labels()
if ax == axs[0]:
# we want to have two legends, let's save the first one
# which just shows the colors and the different SSPs here
leg1 = ax.legend(handles[:3], labels[:3], title='Scenario')
ax.set_ylabel(r'Volume (km$^3$)')
# create the second one, that shows the different statistical estimates
ax.legend([handles[0],handles[3],handles[4]],
['median',labels[3],labels[4]], loc='lower left')
# we need to allow for two legend, this is done like that
ax.add_artist(leg1)
else:
# for the second plot, we only want to have the legend for mean and std
ax.legend(handles[::3], labels[::3], loc='lower left')
ax.set_xlabel('Year');
ax.grid()
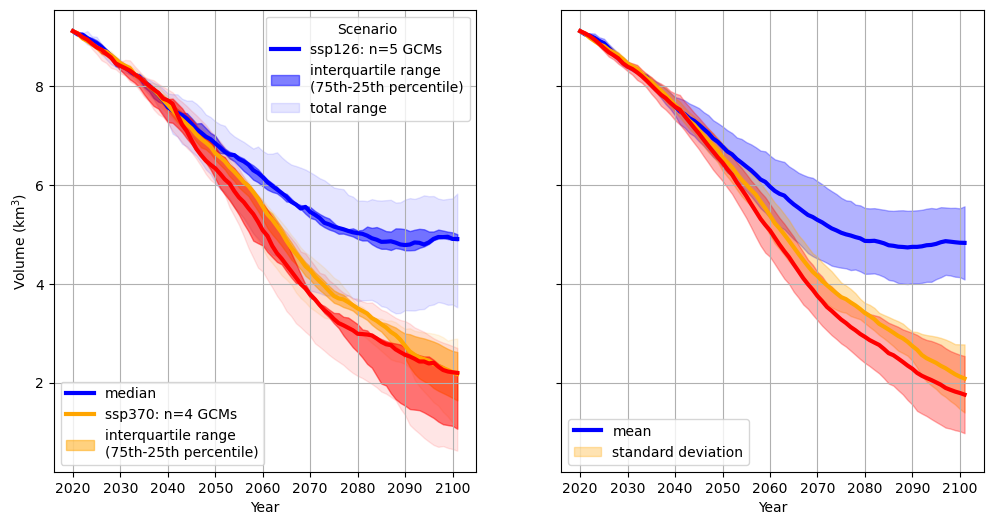
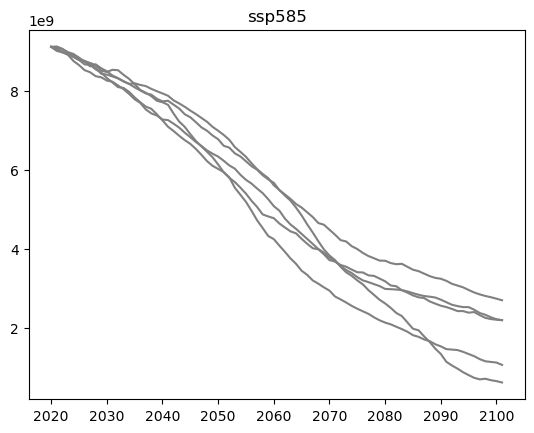
You have to choose which statistical estimate is best in your case. It is also a good possibility to just plot all the scenarios, and then to decide which statistical estimate describes best the spread in your case:
# for example, if there are just 5 GCMs, maybe you can just show all of them?
for gcm in all_GCM:
plt.plot(ds_total_volume.sel(SCENARIO=scenario).time,
ds_total_volume.sel(SCENARIO=scenario, GCM=gcm),
color='grey')
plt.title(scenario)
Text(0.5, 1.0, 'ssp585')
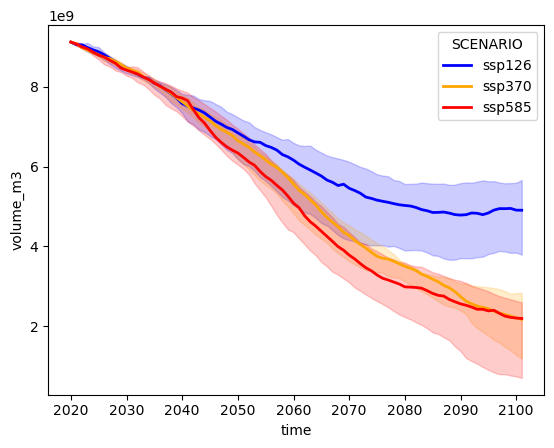
You could create similar plots even easier with seaborn, which has a lot of statistical estimation tools directly included (specifically in seaborn>=v0.12). You can for example check out this errorbar seaborn tutorial. Note that the outcome can be slightly different even for the same statistical estimate as e.g. seaborn and xarray might use different methods to compute the same thing.
import seaborn as sns
# this code might only work with seaborn v>=0.12
# seaborn always likes to have pandas dataframes
pd_total_volume = ds_total_volume.to_dataframe('volume_m3').reset_index()
sns.lineplot(x='time', y='volume_m3',
hue='SCENARIO', # these are the dimension for the different colors
estimator='median', # here you could also choose the mean
data=pd_total_volume,
lw=2, # increase the linewidth a bit
palette= color_dict, # let's use the same colors as before
# for errorbar you could also choose another percentile range
# see: https://seaborn.pydata.org/tutorial/error_bars.html
# "90" means the range goes from the 5th to the 95th percentile
# (50 would be the interquartile range, i.e., the same as two plots above)
errorbar=('pi', 90)
);
Interactive visualisation with HoloViews and Panel#
the following code only works if you install holoviews and panel
We can also visualize the data using tools from the HoloViz framework (namely HoloViews and Panel). For an introduction to HoloViz, you can have a look at the Small overview of HoloViz capability of data exploration notebook.
# Plotting
import holoviews as hv
import panel as pn
hv.extension('bokeh')
pn.extension()


To make your life easier with Holoviews and Panel, you can define a small function that computes your estimates:
In the following section, we only show mean and std, but this could be similar applied to the median and specific percentiles (which might be more robust in your use case :-) ). But just for showing how it works, it is fine to use here mean and std!
def calculate_total_mean_and_std(ds, variable):
mean = ds[variable].sum(dim='rgi_id', # first sum up over all glaciers
skipna=True,
keep_attrs=True,
# important, need values for every glacier
min_count=len(ds_merged.rgi_id),
).mean(dim='GCM', # afterwards calculate the mean of all GCMs
skipna=True,
keep_attrs=True,
)
std = ds[variable].sum(dim='rgi_id', # first sum up over all glaciers
skipna=True,
keep_attrs=True,
min_count=len(ds_merged.rgi_id),
).std(dim='GCM', # afterwards calculate the std of all GCMs
skipna=True,
keep_attrs=True,
)
return mean, std
This function takes a dataset ds and a variable name variable for which the mean and the std should be calculated. This function will come in handy in the next section dealing with the visualisation of the calculated values.
First, we create a single curve for a single scenario (here ssp585):
# calculate mean and std with the previously defined function
total_volume_mean, total_volume_std = calculate_total_mean_and_std(ds_merged, 'volume')
# select only one SSP scenario
total_volume_mean_ssp585 = total_volume_mean.loc[{'SCENARIO': 'ssp585'}]
# plot a curve
x = total_volume_mean_ssp585.coords['time']
y = total_volume_mean_ssp585
hv.Curve((x, y),
kdims=x.name,
vdims=y.name,
).opts(xlabel=x.attrs['description'],
ylabel=f"{y.attrs['description']} in {y.attrs['unit']}")
We used a HoloViews Curve and defined kdims and vdims. This definition is not so important for a single plot but if we start to compose different plots all axis of the different plots with the same kdims or vdims are connected. This means for example whenever you zoom in on one plot all other plots also zoom in. Further, you can see that we have defined xlabel and ylabel using the variable description of the dataset, therefore it was useful to keep_attrs=True when we calculated the total values (see above).
As a next step we can add the std as a shaded area (HoloViews Area) and again define the whole plot as a single curve in a new function:
Create single mean curve with std area#
def get_single_curve(mean, std, ssp):
color = color_dict[ssp]
mean_use = mean.loc[{'SCENARIO': ssp}] # read out the mean of the SSP to plot
std_use = std.loc[{'SCENARIO': ssp}] # read out the std of the SSP to plot
time = mean.coords['time'] # get the time for the x axis
return (hv.Area((time, # plot std as an area
mean_use + std_use, # upper boundary of the area
mean_use - std_use), # lower boundary of the area
vdims=[mean_use.name, 'y2'], # vdims for both boundaries
kdims='time',
label=ssp,
).opts(alpha=0.2,
line_color=None,
) *
hv.Curve((time, mean_use),
vdims=mean_use.name,
kdims='time',
label=ssp,
).opts(line_color=color)
).opts(width=400, # width of the total plot
height=400, # height of the total plot
xlabel=time.attrs['description'],
ylabel=f"{mean_use.attrs['description']} in {mean_use.attrs['unit']}",
)
Overlay different scenarios#
The single curves of the different scenarios we can put together in a HoloViews HoloMap, which is comparable to a dictionary. This further can be easily used to create a nice overlay of all curves.
def overlay_scenarios(ds, variable):
hmap = hv.HoloMap(kdims='Scenarios') # create a HoloMap
mean, std = calculate_total_mean_and_std(ds, variable) # calculate mean and std for all SSPs using our previously defined function
for ssp in all_scenario:
hmap[ssp] = get_single_curve(mean, std, ssp) # add a curve for each SSP to the HoloMap, using the SSP as a key (when you compare it do a dictonary)
return hmap.overlay().opts(title=variable) # create an overlay of all curves
Show different variables in one figure and save as html file#
Now that we have defined how our plots should look like we can compose different variables we want to explore in one plot. To do so we can use Panel Column and Row for customization of the plot layout:
all_plots = pn.Column(pn.Row(overlay_scenarios(ds_merged, 'volume'),
overlay_scenarios(ds_merged, 'area'),
),
overlay_scenarios(ds_merged, 'melt_on_glacier'))
all_plots
When you start exploring the plots by dragging them around or zooming in (using the tools of the toolboxes in the upper right corner of each plot) you see that the x-axes are connected. This makes it very convenient for example to look at different periods for all variables interactively.
You also can open the plots in a new browser tab by using
all_plots.show()
or save it as a html file for sharing
plots_to_save = pn.panel(all_plots)
plots_to_save.save('GCM_runs.html', embed=True)
What’s next?#
return to the OGGM documentation
back to the table of contents